Обзор методов обработки и семантического анализа текста.
Многие компании все больше и больше интересуются методами анализа текстов. Это могут быть запросы клиентов, внутренняя переписка, чаты с клиентами, внутренняя база знаний, обзор прессы или данные парсинга соцсетей.
Все это ставит большой вопрос, каким образом можно анализировать в автоматическом режиме большие объемы данных и позже использовать полученные данные.
Рассмотрим один из перспективных текстовых процессоров на базе Paraphraser.ru. Разработчики сервиса утверждают, что Сервис идеален для анализа:
- Диалогов с клиентами (логов общения).
- Внутренней базы знаний.
- Входящих текстовых запросов.
- Результатов парсинга: соцсетей, прессы и тд.
- Текстов для чат-ботов.
Сервис представлен в виде нескольких модулей, которые способны обрабатывать большие массивы текстов. Анализ текста в модулях реализован статистическими методами с использованием нейронных сетей.

Если коротко, то сравнение 2-х методов обработки текстов можно представить вот таким образом:
Статистические методы
Плюсы:
- Быстрее быстрый и простой метод
- Прозрачность и интерпретируемость результатов
Минусы:
- Необходимость ручной настройки параметров, пороговых значений.
- Менее качественный результат.
Машинное обучение
Плюсы:
- Более высокое качество результата.
- Не требуется ручная настройка.
Минусы:
- Нужны размеченные и обучающие данные.
- Более трудозатратый метод.
- Чёрный ящик (непрозрачность результатов).
При этом полученные результаты можно разделить по таким видам.
Результаты семантического анализа текстов
1. Кластеризация вопросов и ответов:
a. выделение ключевых слов и синонимов,
b. выделение одинаковых по смыслу словосочетаний,
c. выделение однотипных вопросов,
d. выделение однотипных ответов.
e. выделение частотных ключевых слов и синонимов,
f. выделение смысловых сочетаний ключевых слов с другими словами,
g. расчет корреляции (морфологической, семантической, векторной) между словами и словосочетаниями.
2. Определение понятий и смысла в вопросах и ответах:
a. выделение понятий с разными уровнями обобщения (центроиды),
b. расчет корреляционной связи между понятиями в вопросе и понятиями в ответе,
c. построение семантического ряда смыслов
d. расчет кратчайшего пути от вопроса к ответу, корреляция вопросов и уточнений в диалоге и последним или последней группой ответов.
3. Классификация вопросов и ответов.
a. Определение сущностей, определение субъекта, объекта и предмета.
4. Статистический анализ текста:
a. Количество синонимов, семантическое ядро, частотность ключевых слов.
5. Автореферирование текста.
6. Определение пропущенных частей речи.
7. Построение карт смыслов.
8. Классификация текстов исходя из данных WikiPedia.
9. Перефразирование текста.
10. Определение тональности текста.
Со слов разработчиков сервиса – сервис абсолютно не привязан к определенной тематике и не имеет ограничений в части объемов и формата данных.
Когда речь идет о статистическом анализе, то здесь все просто – используются комплексные алгоритмы, но, главное, что результат всегда может быть предсказуем. А вот, что касается машинного обучения, то здесь получается «черный ящик». Никогда не известно заранее, что получится на выходе.

Кроме того, для машинного обучения очень важно иметь размеченные тексты. Иными словами, если текст не имеет оценки: верно / неверно или заранее не был классифицирован пользователем, то система сама сделать классификацию не сможет – ей необходимо показать примеры, только после этого нейросеть начинает работать.
Вот пример обработки текста чата одного коммерческого банка.
Используем статистический метод обработки текста, получаем:
Самые частотные словосочетания (с весами):
- Открытие счета – 41%;
- Закрытие счета — 34%.
Словосочетания (без весов) ТОП 10:
- счет + открытие
- счет + закрытие
- платеж + не уходит
- платеж + завис
- платеж + ошибка
- платеж + на обработке
- поручение + не исполнено
- поручение + на исполнении
- поручение + на обработке
- поручение + отозвать
Вот так может выглядеть графический интерфейс выдачи результатов анализа.
Результаты обработки семантики текста
Топ 30 клиентских запросов

Топ 30 клиентских ключевых слов
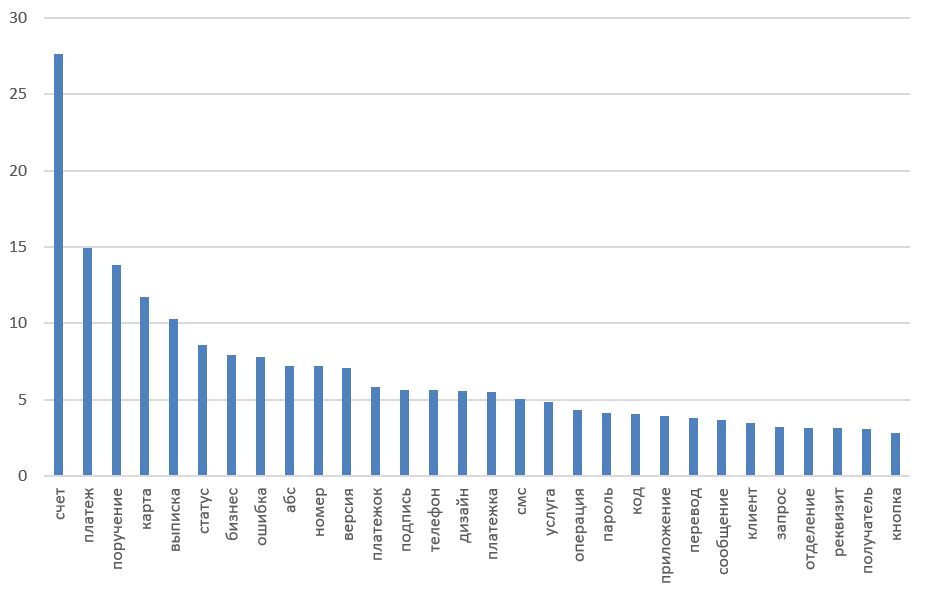
ТОП 30 ответов менеджера

Связи между ключевыми словами

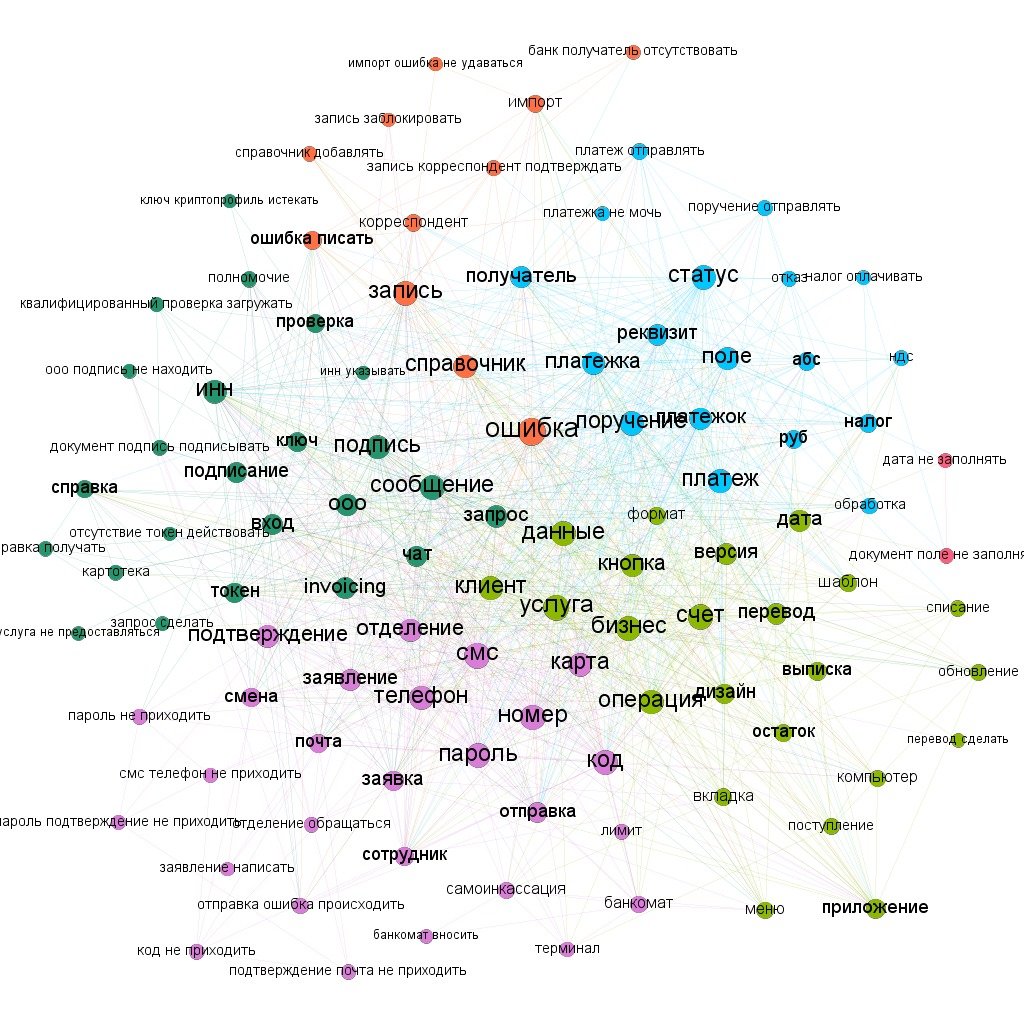
Стоит отметить огромные возможности и потенциал данного сервиса. Сервис представляется по закрытой подписке и может быть настроен и кастомизирован под каждую отдельную задачу.
Со слов разработчиков все задачи могут быть вынесены в контур безопасности клиента, что, безусловно, очень важно, когда речь идет о большом массиве данных, особенно, содержащих персональные данные.
Будем следить за обновлениями и анонсами работы и результатов анализа текстов компанией ParaPhraser.ru